Introduction to Kafka Architecture
1. Overview
카프카는 링크드인에서 개발한 Message Queue 시스템이다. 실시간 로그 처리에 사용되는 아키텍쳐로 대용량 처리에 적합하다.
카프카는 Producer, Consumers, Cluster(Brokers)로 구성된다.
1) Producer는 데이터를 생성하여 카프카로 전송한다.
2) Consumer는 Cluster로부터 데이터를 전달받는다.
3) Cluster는 Producer가 전송한 데이터를 Consumer가 소비할 때까지 보관한다.
* (정확하지는 않습니다. 밑에 자세히 설명하겠습니다.)
카프카는 Pub/Sub 모델을 이용하여 Producer는 자신이 생성/전달하는 데이터의 Topic를 설정할 수 있게 하였고, Consumer는 자신이 원하는 Topic 데이터만 받을 수 있게 설정할 수 있다.
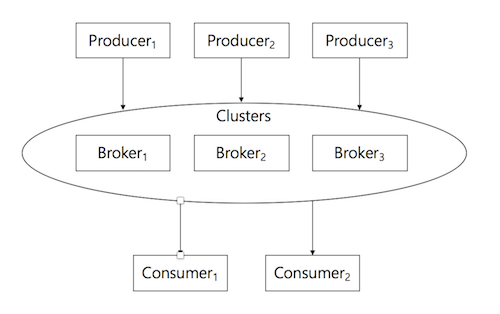
(Simple Kafka Architecture)
2. Topic
위에서 말했듯이, 카프카는 pub/sub 모델을 사용하여 Message에 Topic이라는 개념을 사용한다.
Topic은 publish된 message의 카테고리라고 할 수 있다.
한 Topic에는 다수의 Consumer가 데이터를 받아올 수 있다.
하나의 Topic에 여러 Consumer가 붙을 수 있기 때문에, 한 Consumer가 데이터를 소진하였다고해서 Cluster에서 데이터를 삭제하지 않고, 일정시간동안 유지한다. 이 기간을 retention이라고 하고, user/operator가 직접 configuration 파일에서 설정할 수 있다.
(이 기간 동안 반드시 데이터가 유지된다. 이 기간이 지나면 데이터가 Consumer에 의해 데이터가 소비되지 않아도 삭제된다.)
또한, 각 Consumer가 Topic에서 데이터를 어디까지 소비하였는지 알기 위해서, Consumer 별로 offset을 유지한다.
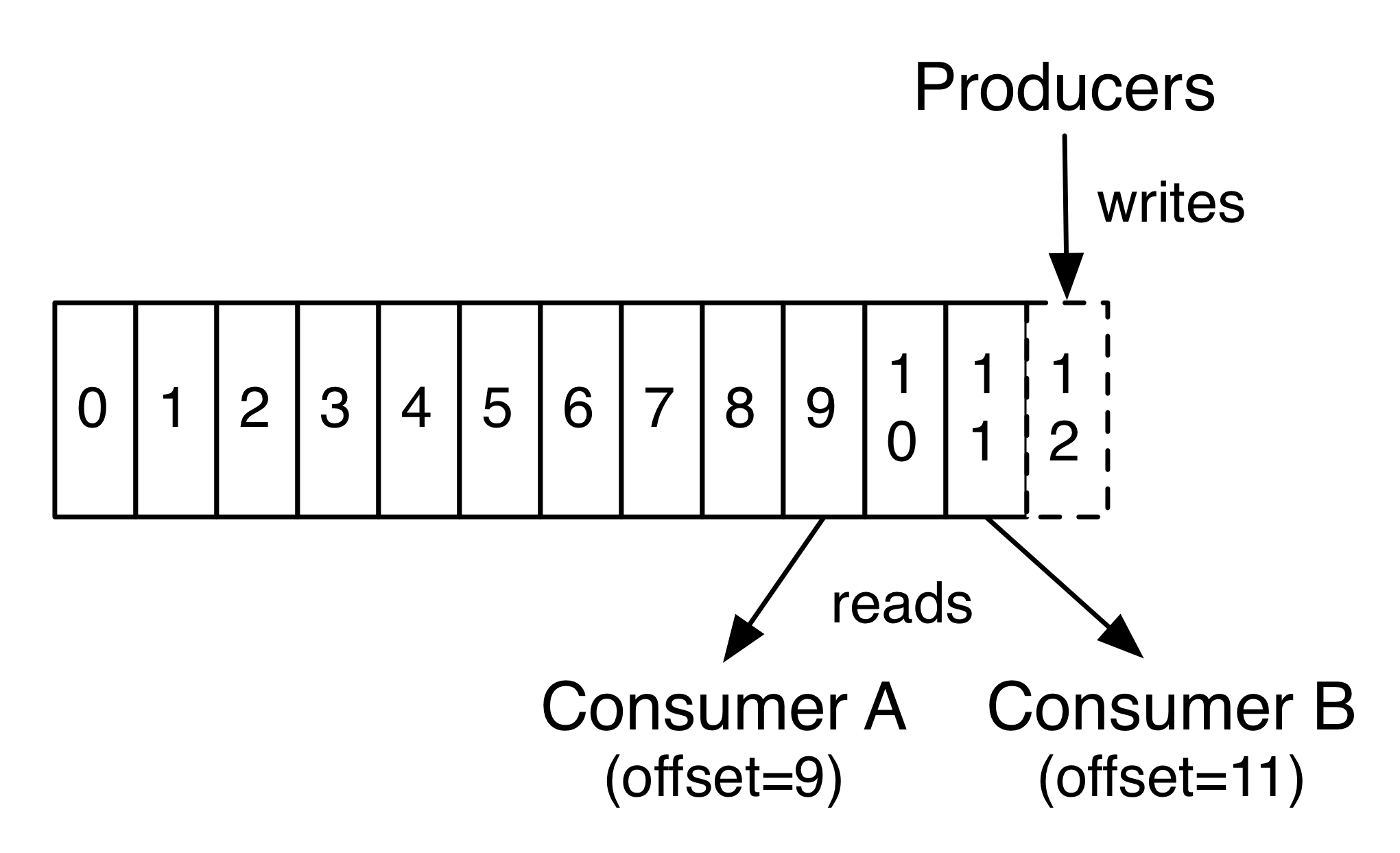
3. Partition
카프카는 하나의 Topic의 병렬처리를 지원하기 위해서 파티션(partition)이라는 기능을 제공한다. 각 파티션은 producer가 보낸 데이터를 동일하게 유지한다.
여러 Consumer들은 원하는 partition에서 데이터를 소진할 수 있다.
Replica와 partition의 수를 잘 조절하면 데이터를 안전하게 보관하면서, 병렬로 처리할 수 있다.
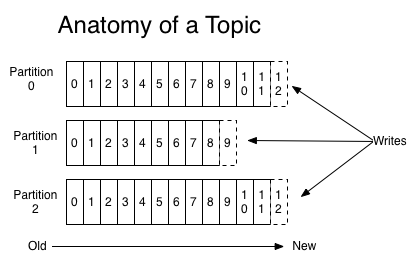
4. Consumer Group
Producer와 달리 Consumer에는 Consumer Group을 지정할 수 있다.(Producer는 같은 Topic으로 데이터를 같이 생성하면 Group이라고 할 수 있다.)
Consumer Group은 여러 Consumer들이 Topic의 offset을 공유하면서 마치 한 Consumer처럼 일을 처리한다. 따라서 Consumer가 데이터를 소비하고 처리할 것이 많아 병렬처리를 하고 싶거나, Consumer의 HA(High Availability)을 지원하고 싶다면 이 기능을 사용할 수 있다.
Reference: kafka documentation