Premade Estimators
이번 문서에서는 Tensorflow 프로그래밍 환경을 소개하고 Tensorflow을 이용하여 아이리스 분류 문제를 어떻게 해결하는지 보여드릴 것 입니다.
Prerequisites(전제 조건)
여기 예제 코드를 사용하기에 앞서, 다음 부분들을 준비해주세요.
- 텐서플로우 설치.
- 텐서플로우를 virtualenv나 Anaconda를 이용해서 설치하셨다면, tensorflow 환경을 활성화(activate)해주세요.
- 다음 명령어를 입력하여 pandas를 다운로드 받거나 업그레이드해주세요.
Getting the sample code(예제코드 받기)
이 문서에서 사용할 예제코드는 다음과 같은 방법으로 다운로드 받을 수 있습니다.
- 다음 명령어로 깃 허브에 있는 텐서플로우 모델 레포지토리(repository)를 다운로드 받으세요.
git clone https://github.com/tensorflow/models- 디렉토리 위치를 다음과 같이 바꿔서 예제 코드가 있는 곳으로 working directory를 바꿔주세요.
cd models/samples/core/get_started/이번 가이드에서는 premade_estimatory.py 파일을 다룰 것 입니다. premade_estimator.py는 트레이닝 데이터를 얻기 위해서 iris_data.py를 사용합니다.
Running the Program(프로그램 실행)
Tensorflow 프로그램 실행은 Python 프로그램 실행과 같습니다. 예를 들어서,
python premade_estimator.py프로그램을 실행하면 트레이닝 로그와 함께 테스트 데이터에 대한 예측 결과값이 출력됩니다. 예를 들어, 첫 번째 줄 출력은 (학습한) 모델이 Setosa 테스트 케이스에 대해서 99.6% 확률로 생각(think)하는 것을 보여줍니다. Setosa test set이 예측되었기 때문에, 모델이 좋은 예측을 한 것으로 사료됩니다.(Since the test set expected Setosa, this appears to be a good prediction.)
...
Prediction is "Setosa" (99.6%), expected "Setosa"
Prediction is "Versicolor" (99.8%), expected "Versicolor"
Prediction is "Virginica" (97.9%), expected "Virginica"프로그램이 모델의 예측값 대신에 에러를 출력한다면, 다음과 같은 부분을 고려해보세요.
- Tensorflow를 잘 설치하였나요?
- 적절한 버전의 Tensorflow를 설치하였나요?
- Tensorflow를 설치한 환경을 활성화(activate)하였나요? (virtualenv 또는 Anaconda 사용자)
The programming stack(프로그램 스택)
코드를 살펴보기에 앞서, 먼저 개발 환경을 알아보겠습니다. 다음 그림에서 보듯이, Tensorflow는 여러 단계의 API로 구성된 프로그래밍 스택을 제공합니다.
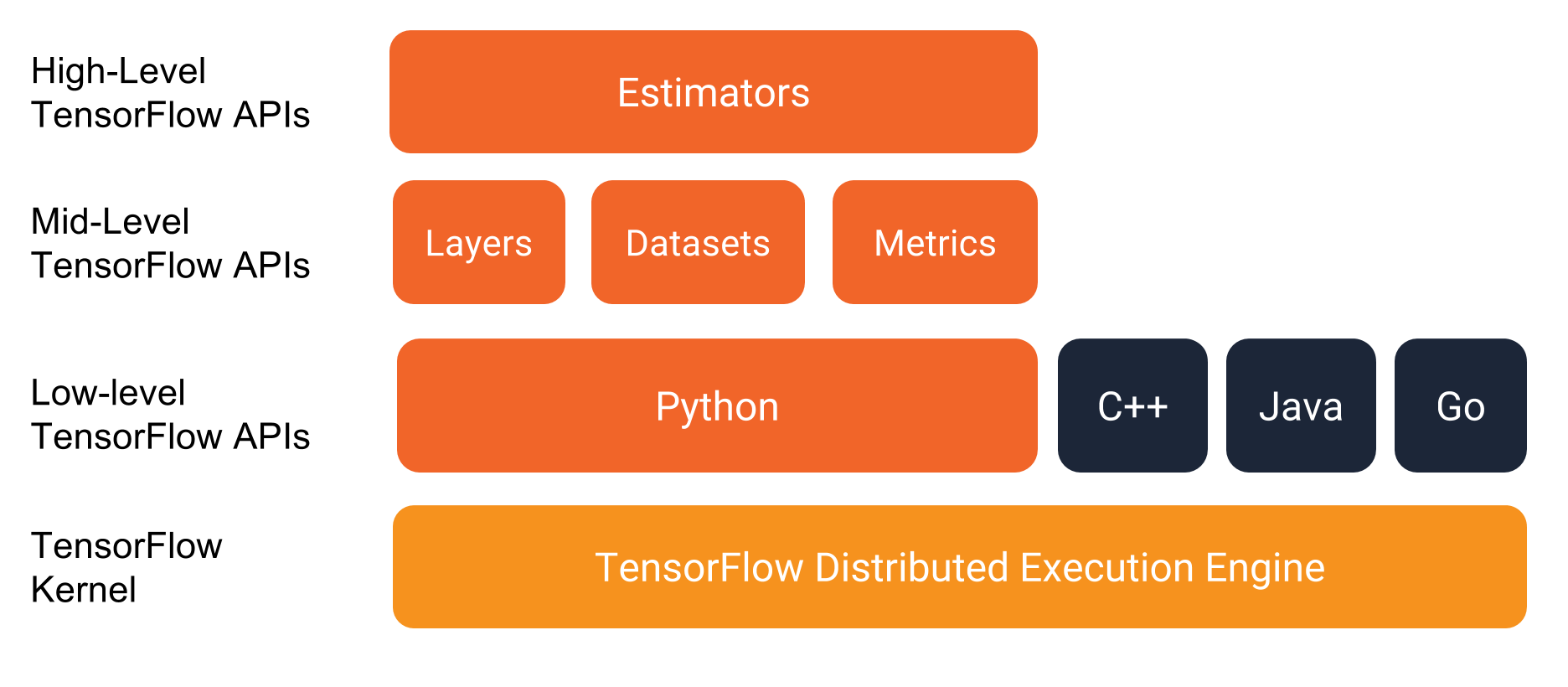
Tensorflow 프로그램을 구현할 때, Estimators와 Datasets을 사용하는 권장합니다.
- Estimators: Estimators는 완전한 모델입니다. Estimators API는 모델을 학습하고, 모델의 정확도를 측정하고, 예측값을 생성하는 함수를 제공합니다.
- Datasets: Datasets 클래스는 Estimators를 위해 데이터 입력 파이프라인을 생성합니다. Datasets API는 데이터를 부르고, 정제(조정)하고, 모델에 넣어줍니다. DataSets API는 Estimators와 잘 작동합니다.
Classifying irises: an overview(아이리스 분류: 개요)
이번 문서에서 사용하는 예제 프로그램은 꽃의 꽃받침과 꽃잎의 길이로 아이리스 꽃을 3개의 종으로 분류하는 모델을 만들고 테스트합니다.
꽃잎의 기하학적 구조는 다음 그림에서 보실 수 있습니다. 왼쪽부터 Iris setosa(by Radomil, CC BY-SA 3.0), Iris virginica(by Dlanglois, CC BY-SA 3.0), 그리고 Iris versicolor(by Frank Mayfield, CC BY-SA 2.0) 입니다.
The data set
아이리스 데이터는 4개의 특성(feature)과 하나의 레이블(label)로 구성되어있습니다. 4개의 특징은 각각 꽃들의 식물학적 특성을 나타냅니다.
- 꽃받침의 길이
- 꽃받침의 너비
- 꽃잎의 길이
- 꽃잎의 너비
우리가 생성한 모델은 4개의 특성을 float32로 표현합니다.
레이블은 Iris 꽃 종을 의미합니다. 0은 Iris setosa, 1은 Iris versicolor, 2는 Iris virginica 입니다. 우리가 생성한 모델은 레이블을 int32 데이터로 표현합니다.
다음 테이블은 예제 데이터에서 3개의 예제를 보여줍니다.
| sepal length | sepal width | petal length | petal width | species (label) |
|---|---|---|---|---|
| 5.1 | 3.3 | 1.7 | 0.5 | 0 (Setosa) |
| 5.0 | 2.3 | 3.3 | 1.0 | 1 (versicolor) |
| 6.4 | 2.8 | 5.6 | 2.2 | 2 (virginica) |
The algorithm
우리 프로그램이 학습시킬 Deep Neural Network 분류기 모델은 다음과 같은 위상(topology)를 가지고 있습니다.
- 2개의 hidden layers
- 각 레이어에 10개의 노드들(뉴런)
다음 그림은 Deep Neural Network 의 특성(features), 히든 레이어(hidden layers), 그리고 predictions(output layer) 부분을 보여주고 있습니다. (그림의 크기 상, 네트워크 내에 있는 모든 노드들을 보여주지는 못 했습니다.)
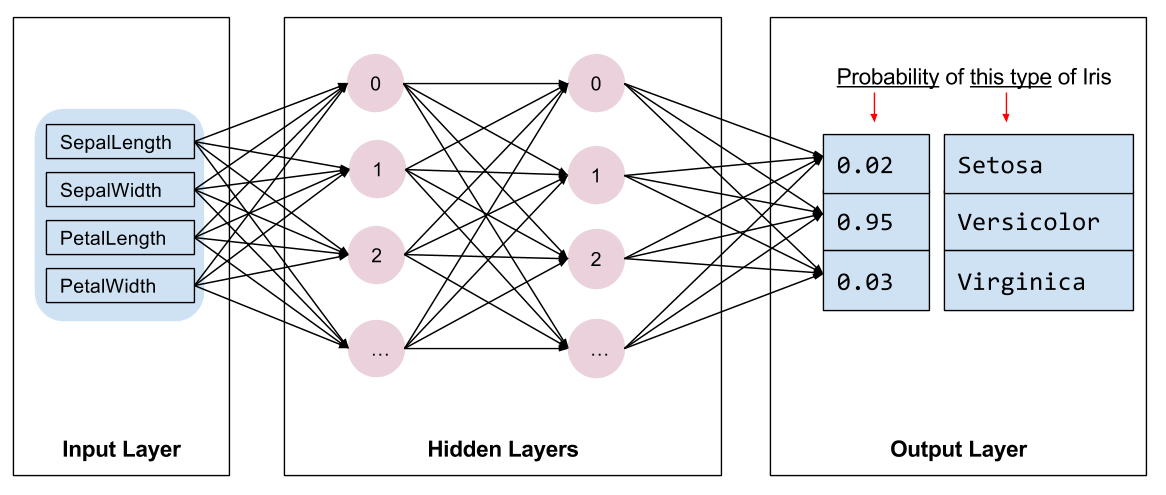
Inference
학습하 모델에 레이블링이 되지 않은 데이터를 넣으면, 모델은 3가지 예측값을 생산합니다. 값은 주어진 데이터에 대한 각 Iris 종일 확률인 우도(likelihood) 값입니다. 출력된 예측값의 합은 1이 됩니다. 예를 들어서, 레이블링 되지 않은 예제데이터를 넣으면, 다음과 같은 예측 값이 나옵니다.
Iris Setosa: 0.03, Iris Versicolor: 0.95, Iris Virginica: 0.02
위의 데이터는 95%의 확률로 Iris Versicolor라고 학습된 모델은 예측하고 있습니다.
Overview of programming with Estimators(프로그래밍 개요-Estimators)
Estimator는 완성된 모델들의 하이레벨 API(representation) Tensorflow 입니다. Estimator는 초기화(initialization)의 자세한 부분, 로깅, 저장과 복원 그리고 다른 특징들을 세부적으로 다루고 있어, 우리가 모델에 집중할 수 있게 해줍니다. Estimators에 대한 더 자세한 사항은 Estimator를 참고하세요.
tf.estimator.Estimator로부터 파생된(상속받은) 클래스는 모두 Estimator 입니다. Tensorflow는 일반적인 ML 알고리즘을 구현하기 위한 다수의 pre-made Estiomator를 제공하고 있습니다. (예를 들어서, LinearRegressor가 있습니다.). 이 Estimator들을 넘어서 자신만의 Estimator를 구현하고 싶을 수도 있습니다. 그렇지만, 구현을 시작할 때에는 pre-made Estiomator를 사용하는 것이 좋습니다.(권장합니다.)
pre-made Estimator들을 이용하여 Tensorflow 프로그램을 작성할 때, 다음과 같은 작업들을 해야합니다.
- 하나 이상의 입력 함수 작성
- 모델의 특성(feature) 열(column) 작성
- Estimator의 객체를 만들고, 특성 열(feature column)과 다양한 hyperparameter(?)들을 설정한다. (Instantiate an Estimator, specifying the feature columns and various hyperparameters.)
- Estimator 객체의 하나 또는 그 이상의 함수들을 호출하고, 데이터를 제공하기 위해 적절한 입력 함수를 전달한다.
아이리스 문제에서 위의 작업들이 어떻게 구현되는지 확인해보겠습니다.
Create input functions
모델을 학습, 평가하고 모델을 이용하요 예측하려면, 먼저 입력 함수(input function)을 작성해야합니다.
입력 함수(input function)은 tf.data.Dataset 객체를 리턴하는 함수입니다. 해당 객체는 features와 label로 구성된 tuple을 반환합니다.
- features - Python dictionary 타입 객체로 ** key는 각 feature들의 이름입니다. ** value는 해당 feature에 해당하는 모든 값을 가지는 배열입니다.
- label - 모든 데이터에 대해서 레이블 값을 갖는 배열입니다.
다음 간단하게 구현된 코드에서 입력함수에 대한 형식(format)을 보여줍니다.
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels원하는 방식으로 입력 함수가 feature dictionary와 label list를 생성할 수 있도록 구현하세요. 하지만 우리는 Tensorflow의 Dataset API를 권장합니다. Dataset API를 이용하면 모든 종류의 data를 parsing할 수 있습니다. 높은 레벨(high level)에서, Dataset API는 다음과 같은 클래스로 구성되어있습니다.
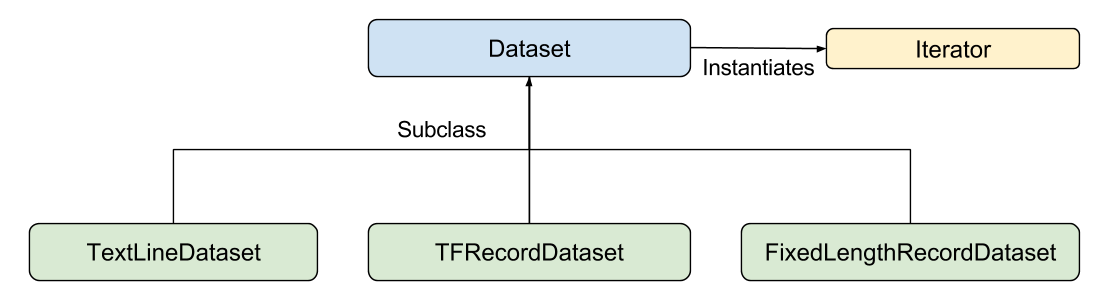
각 클래스에 대한 설명은 다음과 같습니다.
- Dataset - Dataset을 생성하고 변경할 수 있는 함수를 갖고 있는 기본적인 클래스입니다. 또한, 메모리에 있는 데이터 또는 파이썬 생산자(generator)로부터 Dataset을 초기화(initialize)할 수 있도록 지원합니다.
- TextLineDataset - 텍스트 파일로부터 데이터 라인(line)을 읽어드립니다.
- TFRecordDataset - TFRecord 파일로부터 레코드(record)를 읽어드립니다.
- FixedLengthRecordDataset - 바이너리 파일로부터 고정된 크기의 데이터를 읽습니다.
- Iterator - 한 순간에 데이터 원소(element)에 접근할 수 있는 방법을 제공합니다.
Dataset API는 다양한 일반적인 경우(데이터)를 다룰 수 있게 합니다. 예를 들어, Dataset API를 사용하면, 다수의 파일로부터 레코드를 병렬적으로 불러와 하나의 스트림으로 합칠(join) 수 있습니다.
이번 문서에서는 쉽게하기 위해서, data를 pandas를 이용해 읽어드리고, 메모리에 있는 데이터를 읽어드리는 input pipeline을 구축할 것입니다.
다음 input 함수는 이번 문서에서 학습을 위해 사용하는 함수입니다. iris_data.py 코드에 있습니다.
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
return dataset.shuffle(1000).repeat().batch(batch_size)Define the feature columns
feature column은 feature dictionary의 데이터를 모델이 어떻게 사용해야되는지 알려주는 객체입니다. Estimator 모델을 만들 때, 모델이 사용해야하는 feature들을 설명하는 feature column 리스트를 전달해야합니다. tf.feature_column 모듈은 모델에게 데이터를 설명하는 여러가지 옵션들을 제공합니다.
아이리스 문제에서는 각각 숫자 값인 4개의 feature 을 사용합니다. Estimator에게 각각의 feature들이 32-bit floating-point 값이라는 것을 알려줄 feature column 리스트를 만듭니다. 다음 코드는 feature column을 생산하는 코드입니다.
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))Feature column들은 위에 코드보다 훨씬 복잡해질 수 있습니다. feature column에 대한 자세한 설명은 Getting Started guide의 뒷 부분에서 더 진행하겠습니다.
이제 feature들을 모델에서 어떻게 사용해야하는지 설명할 수 있기 때문에, estimator를 만들어낼 수 있습니다.
Instantiate an estimator
아이리스 문제는 고전적인 분류(classification) 문제입니다. 운 좋게도, Tensorflow는 여러 가지 pre-made classifier Estimator를 제공합니다.
- tf.estimator.DNNClassifier: 멀티 클래스(label이 2개 이상) 분류 문제에 사용되는 딥러닝 모델입니다.
- tf.estimator.DNNLinearCombinedClassifier: for wide & deep models(?).
- tf.estimator.LinearClassifier: 리니어 모델을 기본으로하는 분류기(classifier)입니다.
아이리스 문제에서는 tf.estimator.DNNClassifier를 사용하는 것이 제일 좋을 것 입니다. 다음 코드에서 우리는 Estimator를 어떻게 시작하는지(instantiate) 보여줍니다.
# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)Train, Evaluate, and Predict
이제 우리는 Estimator 객체를 갖고 있고, 다음과 같은 함수를 호출할 수 있습니다.
- 모델을 학습
- 학습된 모델을 평가
- 학습된 모델을 이용하여 예측
Train the model
모델을 학습하기 위해서는 Estimator’s train 함수를 호출해야합니다.
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)input_fn 함수를 lambda로 함수로 한 번 감싸(wrap)서 보내줍니다. 이렇게 하면, input_fn의 argument는 없지만, lambda로 감싸진 함수 train_input_fn에는 argument를 추가할 수 있습니다. steps 인자는 함수에게 해당 steps 수만큼 트레이닝을 하도록 하게할 수 있습니다.
Evaluate the trained model
모델을 학습하고나면, 모델의 성능에 대해 통계 결과를 얻을 수 있습니다. 다음 코드 블럭은 테스트 데이터에 대한 학습된 모델의 정확도를 측정합니다.
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\\nTest set accuracy: \{accuracy:0.3f\}\\n'.format(\*\*eval_result))train 함수를 호출할 때와 달리, steps 인자를 evaluate 함수에 전달하지 않습니다. eval_input_fn은 데이터에 대해서 한 번만 수행합니다. (a single epoch)
이 코드를 수행하면 다음과 같은 결과 값이 나옵니다.(또는 비슷한 결과값이 나옵니다.)
Test set accuracy: 0.967Making predictions (inferring) from the trained model
적절한 값을 생성하는, 즉 학습이 잘 된 모델을 구했습니다. 이제, 학습된 모델을 이용하여 label 되지 않은 데이터에 대한 Iris 꽃 종류를 예측할 수 있습니다. 학습하고 평가하고나서, 다음 한 함수를 호출하면 예측 값을 구할 수 있습니다.
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
batch_size=args.batch_size))predict 함수는 prediction result를 갖고 있는 Python의 iterable한 dictionary 객체를 반환합니다. 다음 코드는 몇몇 예측 값과 그 확률을 출력하고 있습니다.
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
for pred_dict, expec in zip(predictions, expected):
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(iris_data.SPECIES[class_id],
100 * probability, expec))위의 코드를 실행하면 다음과 같은 결과 또는 비슷한 값이 나옵니다.
...
Prediction is "Setosa" (99.6%), expected "Setosa"
Prediction is "Versicolor" (99.8%), expected "Versicolor"
Prediction is "Virginica" (97.9%), expected "Virginica"Summary
Pre-made Estimator는 보통 수준의 모델을 효과적으로 빠르게 만들 수 있게 해줍니다.
Tensorflow 프로그램을 구현할 때, 다음과 같은 부분을 고려해야합니다.
- Checkpoints: 모델을 저장하고 불러오는 방법에 대해서 알아봅니다.
- Datasets for Estimators: 데이터를 불러와(import) 모델에 넣는 방법에 대해서 알아봅니다.
- Creating Custom Estimators: 자신만의 Estimator를 작성하고, 특정 문제를 해결하기 위해 커스터마이즈 하는 방법을 알아봅니다.